2024. 5. 23. 18:12ㆍ딥러닝
- Conv2DTranspose layer를 이용한 Image Segmentation Baseline 구현
- Image Classification으로는 MaxPooling이 괜찮지만, Image Segmentation Task에서는 Stride가 2인게 Down Sampling시에 괜찮다.
1. 세가지 주요 컴퓨터 비전 작업
- 이미지 분류(Image Classification)
- 이미지 분할(Image Segmentation)
- 객체 탐지(object detection)

또한 컴퓨터 비전을 위한 딥러닝을 위 세 가지 이외에도 여러 가지 틈새 분야에 해당하는 작업이 있습니다. 예를 들어 이미지 유사도 평가(image similarity scoring)(두 이미지가 시각적으로 얼마나 비슷한 지 추정하기), 키포인트 감지(keypoint detection)(얼굴 특징과 같이 이미지에서 관심 속성을 정확히 짚어 내기), 포즈 추정(pose estimation), 3D 메시 추정(mesh estimation) 등입니다.
이미지 분할 예제
- 시맨틱 분할(semantic segmentation) : 각 픽셀이 독립적으로 ‘cat’과 같은 하나의 의미를 가진 범주로 분류됩니다.
- 인스턴스 분할(instance segmentation) : 이미지 픽셀을 분류하는 것 뿐만 아니라 개별 객체 인스턴스를 구분합니다.

분할 마스크(segmetation mask)는 이미지 분할에서 레이블에 해당합니다. 입력 이미지와 동일한 크기의 이미지고 컬러 채널은 하나입니다. 각 정수 값은 입력 이미지에서 해당 픽셀의 클래스를 나타냅니다. 이 데이터셋의 경우 분할 마스크의 픽셀은 3개의 정수 값 중 하나를 가집니다.
- 1(전경), 2(배경), 3(윤곽)
먼저 wget과 tar 셸 명령어로 데이터셋을 내려받고 압축을 풉니다.
!wget <http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz>
!wget <http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz>
!tar -xf images.tar.gz
!tar -xf annotations.tar.gz
입력 사진은 images/ 폴더에 JPG 파일로 저장되어 있습니다.
입력 파일 경로와 분할 마스크 파일 경로를 각각 리스트로 구성해보겠습니다.
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])
입력과 분할 마스크는 다음과 같은 형태를 하고 잇습니다.
import matplotlib.pyplot as plt
from tensorflow.keras.utils import load_img, img_to_array
plt.axis("off")
plt.imshow(load_img(input_img_paths[9]))

def display_target(target_array):
normalized_array = (target_array.astype("uint8") - 1) * 127
plt.axis("off")
plt.imshow(normalized_array[:, :, 0])
img = img_to_array(load_img(target_paths[9], color_mode="grayscale"))
display_target(img)

그 다음 입력과 타깃을 2개의 넘파일 배열로 로드하고 이 배열을 훈련과 검증 세트로 나눕니다. 데이터셋이 매우 작기 때문에 모두 메모리로 로드할 수 없습니다.
import numpy as np
import random
img_size = (200, 200)# 이후에 입력과 타깃을 200 x 200의 크기로 변경할 예정
num_images = len(input_img_paths)# 데이터에 있는 전체 샘플의 개수
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
def path_to_input_image(path):
return img_to_arry(load_img(path, target_size=img_size))
def path_to_target(path):
img = img_to_array(
load_img(path, target_size=img_size, color_mode="grayscale")
)
img = img.astype("uint8")# 레이블이 0, 1, 2rk dhehfhr gkqslek.
return img
# 전체 이미지를 input_imgs에 float32 배열로 로드하고 타깃 마스크는 targets에 uint8로 로드 합니다.(같은 순서로)# 입력은 3개의 채널(RGB)을 가지고 타깃은 (정수 레이블을 담은) 하나의 채널을 가집니다.
input_images = np.zeros((num_images,) + img_size + (3, ), dtype="float32")
targets = np.zeros((num_images,) + img_size + (1,), dtype="uint8")
for i in range(num_imgs):
input_imgs[i] = path_to_input_image(input_img_paths[i])
targets[i] = path_to_target(target_paths[i])
num_val_samples = 1000# 검증에 1000개의 샘플을 사용합니다.
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]
모델 정의
from tensorflow import keras
from tensorflow.keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape=img_size + (3,))
x = layers.Rescaling(1./255)(inputs)# 입력 이미지를 [0-1] 범위로 만듭니다.# padding이 특성 맵(Feature Map) 크기에 영향을 미치지 않도록 모두 padding="same"으로 지정합니다.
x = layers.Conv2D(64, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, strides=2, activation="relu", padding="same")(x)
x = layers.Conv2D(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(256, 3, strides=2, padding="same", activation="relu")(x)
x = layers.Conv2D(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(256, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(128, 3, activation="relu", padding="same", strides=2)(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same")(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", padding="same", strides=2)(x)
# 각 출력 픽셀을 3개의 범주 중 하나로 분류하기 위해 3개의 필터와 소프트 맥스 활성화 함수를 가진 Conv2D 층으로 모델을 종요합니다.
outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x)
model = keras.Model(inputs, outputs)
return model
model = get_model(img_size=img_size, num_classes=3)
model.summary()
'''
출력 결과
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 200, 200, 3)] 0
rescaling (Rescaling) (None, 200, 200, 3) 0
conv2d (Conv2D) (None, 100, 100, 64) 1792
conv2d_1 (Conv2D) (None, 100, 100, 64) 36928
conv2d_2 (Conv2D) (None, 50, 50, 128) 73856
conv2d_3 (Conv2D) (None, 50, 50, 128) 147584
conv2d_4 (Conv2D) (None, 25, 25, 256) 295168
conv2d_5 (Conv2D) (None, 25, 25, 256) 590080
conv2d_transpose (Conv2DTra (None, 25, 25, 256) 590080
nspose)
conv2d_transpose_1 (Conv2DT (None, 50, 50, 256) 590080
ranspose)
conv2d_transpose_2 (Conv2DT (None, 50, 50, 128) 295040
ranspose)
conv2d_transpose_3 (Conv2DT (None, 100, 100, 128) 147584
ranspose)
conv2d_transpose_4 (Conv2DT (None, 100, 100, 64) 73792
ranspose)
conv2d_transpose_5 (Conv2DT (None, 200, 200, 64) 36928
ranspose)
conv2d_6 (Conv2D) (None, 200, 200, 3) 1731
=================================================================
Total params: 2,880,643
Trainable params: 2,880,643
Non-trainable params: 0
_________________________________________________________________
'''
이 모델의 처음 절반은 이미지 분류에서 사용하는 컨브넷과 닮앗습니다. Conv2D 층을 쌓고 점진적으로 필터 개수를 늘립니다. 이미지를 절반으로 세 번 다운 샘플링(down sampling)하여 마지막 합성 곱 층의 활성화 출력은 (25, 25, 256)으로 끝납니다. 이 모델에서 처음 절반의 목적은 이미지를 작은 특성 맵으로 인코딩하는 것입니다. 공간상의 각 위치(픽셀)은 원본 이미지에 있는 더 큰 영역에 대한 정보를 담고 있습니다. 이를 일종의 압축으로 이해할 수 있습니다.
이 모델의 처음 절반과 이전에 보았던 분류 모델 사이의 큰 차이점은 다운 샘플링 방식입니다. 이전 장의 이미지 분류 컨브넷은 MaxPooling2D 층을 사용하여 특성 맵을 다운 샘플링 했습니다. 여기에서는 학성곱 층마다 스트라이드(stride)를 추가하여 다운 샘플링을 합니다. 이미지 분할의 경우 모델의 출력으로 픽셀별 타깃 마스크를 생성해야 하므로 정보의 공간상 위치에 많은 관심을 두기 때문입니다. 2 x 2 MaxPooling을 사용하면 풀링 윈도우 안의 위치 정보가 완전히 삭제됩니다. 윈도우마다 하나의 스칼라 값을 반환하며 이 값이 윈도우 내의 네 위치 중 어디에서 왔는지 전혀 정보가 없습니다. 따라서 최대 풀링은 분류 작업에는 잘 맞지만 분할 작업에는 상당한 해를 끼칠 수 있습니다. 반면 스트라이드 합성곱은 위치 정보를 유지하면서 특성맵을 다운 샘플링하는 작업에 더 잘맞습니다.
이 모델의 나머지 절반은 Conv2DTranspose 층을 쌓은 것입니다. 이 층은 앞서 했던 다운 샘플링을 거꾸로 적용하는 방법이라고 이해하면 좋습니다. 즉, 다운 샘플링이 아니라 특성 맵을 업 샘플링(upsampling)하는 것입니다. 이것이 Conv2DTranspose 층을 두는 목적입니다.
이제 모델을 컴파일하고 훈련합니다.
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
batch_size=64,
validation_data=(val_input_imgs, val_targets))
CallBack으로 save_best_only=True로 했으므로, val_loss가 최고인 모델만 저장될 예정입니다. 해당 가중치 모델을 로드해 Segmentation Masking을 예측하는 방법을 알아보겠습니다.
from tensorflow.keras.utils import array_to_img
model = keras.models.load_model("oxford_segmentation.keras")
i = 4
test_image = val_input_imgs[i]
plt.axis("off")
plt.imshow(array_to_img(test_image))
mask = model.predict(np.expand_dims(test_image, 0))[0]
def display_mask(pred):
mask = np.argmax(pred, axis=-1)
mask *= 127
plt.axis("off")
plt.imshow(mask)
display_mask(mask)
3. 최신 컨브넷 아키텍쳐 패턴
모델의 아키텍쳐(architecture)는 모델을 만드는데 사용된 일련의 선택입니다. 사용할 층, 층의 설정, 층을 연결하는 방법 등입니다. 이런 선택이 모델의 가설 공간(hypothesis space)을 정의합니다. 경사 하강법이 검색할 수 있는 가능한 함수의 공간으로 파라미터는 모델의 가중치입니다. 특성 공학과 마찬가지로 좋은 가설 공간은 현재 문제와 솔루션에 대한 사전 지식(prior knowledge)을 인코딩합니다. 예를 들어 합성곱 층을 사용한다는 것은 입력 이미지에 있는 패턴이 이동 불변성이 있음을 미리 알고 있다는 뜻입니다. 데이터에서 효율적으로 학습하기 위해 찾고 있는 것에 대한 가정을 해야합니다.
모델 아키텍쳐는 과학보다는 예술에 가깝습니다. 숙련된 머신 러닝 엔지니어는 첫 번째 시도에서 고성능 모델을 직관적으로 조합할 수 있습니다. 하지만 초보자는 종종 훈련된 모델을 만드는 데 어려움을 겪습니다. 여기에서 키워드는 “직관적”입니다. 누구도 어떤 것이 잘되고 어떤 것이 잘 안되는 명확하게 설명할 수 없습니다. 전문가는 다양한 실전 경험을 통해 얻은 능력인 패턴 매칭에 의존합니다.
이어지는 절에서 몇 가지 핵심적인 컨브넷 아키텍처의 모범 사례를 알아보겠습니다. 특히 잔차 연결(residual connection), 배치 정규화(batch normalizaton), 분리 합성곱(separable convolution)입니다.
3.1 모듈화, 계층화 그리고 재사용
복잡한 시스템을 단순하게 만들고 싶다면 일반적으로 적용할 수 있는 방법이 있습니다. 수프처럼 형태를 알아보기 힘든 복잡한 구조를 모듈화(modularity)하고, 모듈을 계층화(hierarchy)하고, 같은 모듈을 적절하게 여러 곳에서 재사용(reuse)하는 것입니다.(여기에서 재사용은 추상화(abstraction)의 다른 말입니다.) 이것이 MHR(Modularity-Hierarchy-Reuse) 공식입니다. 아키텍쳐(architecture)라는 용어가 사용되는 거의 모든 영역에 있는 시스템 구조의 기초가 됩니다. 대성당, 사람의 몸, 미국 해군, 케라스 코드를 포함하여 의미 있는 복잡성을 가진 모든 시스템 조직의 핵심입니다.
소프트웨어 엔지니어라면 이미 다음과 같은 원칙을 잘 알고 있을 것입니다. 효율적인 코드는 모듈화되고 계층적이며 동일한 것을 두 번 구현하지 않습니다. 그 대신 재사용 가능한 클래스와 함수를 사용합니다. 이런 원칙에 따라 코드를 리펙터링하면 이를 “소프트웨어 아키텍쳐”를 수행했다고 말할 수 있습니다.
딥러닝 모델 아키텍쳐는 모듈화, 계층화, 재사용을 영리하게 활용하는 것입니다. 인기 있는 모든 컨브넷 아키텍처는 층으로만 구성되어 있지 않고 반복되는 층 그룹(block) 또는 모듈(Module)으로 구성되어 있습니다. 예를 들어 이전 장에서 사용한 VGG16 구조는 합성곱, 합성곱, 최대 풀링 블록이 반복되는 구조입니다.

계층 구조가 깊으면 특성 재사용과 이로 인한 추상화를 장려하기 때문에 본질적으로 좋습니다. 일반적으로 작은 층을 깊게 쌓은 모델이 큰 층을 얇게 쌓은 것보다 성능이 좋습니다. 하지만 그레이디언트 소실(vanishing gradient) 문제 때문에 층을 쌓을 수 있는 정도에 한계가 있습니다. 이런 문제가 첫 번째 핵심 아키텍처 패턴인 잔차 연결을 탄생시켰습니다.
딥러닝 연구에서 절제 연구의 중요성
딥러닝 아키텍처는 계획적이라기보다 진화적으로 발전하는 경우가 많습니다. 반복적으로 시도하고 잘 동작하는 것을 선택하여 개발하게 됩니다. 복잡한 딥러닝 구조를 실험하는 경우 생물학적 시스템과 매우 비슷하게 성능의 손실 없이 몇 개의 모듈을 제거할 수 있습니다.
이는 딥러닝 연구자들 앞에 놓은 인센티브 때문에 더욱 악화됩니다. 시스템을 필요 이상으로 복잡하게 만들어 더 흥미롭거나 더 참신하게 보이게 함으로써 논문이 동료 심사(peer review)를 통과할 가능성을 높일 수 있습니다. 많은 딥러닝 논문을 읽어보면 의도적으로 명확한 설명과 신뢰 있는 결과를 피하는 식으로 스타일과 내용면에서 동료 심사에 최적화되어 있는 경우가 많습니다. 예를 들어 딥러닝 논문에 있는 수학은 개념을 명확하게 공식화하거나 뻔하지 않은 결과를 유도하기 위해 사용되는 경우가 드뭅니다. 오히려 비싼 정장을 입은 판매원처럼 진지함의 신호로 사용됩니다.
연구의 목표는 단순히 논문 출판만이 아니라 신뢰할 수 있는 지식을 생성하는 것이어야 합니다. 시스템에서 인과 관계(causality)를 이해하는 것이 신뢰할 수 있는 지식을 생성하는 가장 쉬운 방법입니다. 매우 적은 노력으로 인과 관계를 확인하는 방법이 있습니다. 바로 **절제 연구(ablation study)**입니다. 절제 연구는 체계적으로 시스템의 일부를 제거하여 단순하게 만들고 실제로 어디에서 성능 향상이 오는지 확인하는 것입니다.
3.2 잔차 연결
순차적인 딥러닝 모델에서 역전파는 옮겨 말하기 게임과 매우 비슷합니다. 다음과 같이 함수가 연결되어 있다고 생각해보죠.
$$ y = f_4(f_3(f_2(f_1(x)))) $$
$f_1$을 조정하려면 $f_2, f_3, f_4$에 오차 정보를 통과시켜야 합니다. 하지만 연속적으로 놓인 각 함수에는 일정량의 잡음이 있습니다. 함수 연결이 너무 깊으면 이 잡음이 그레이디언트 정보를 압도하기 시작하고 역전파가 동작하지 않게 됩니다. 즉, 모델이 전혀 훈련되지 않을 것입니다. 이를 **그레디언트 소실(vanishing gradient)**문제라고 합니다.
해결하는 방법은 간단합니다. 연결된 각 함수를 비파괴적으로 만들면 됩니다. 즉, 이전 입력에 담긴 잡음 없는 정보를 유지시킵니다. 층이나 블록의 입력을 출력에 더하기만 하면 됩니다. 이를 구현하는 가장 쉬운 방법이 **잔차 연결(residual connection)**입니다. 이 기법은 2015년(마이크로소프트의 He 등이 개발한) ResNet 모델과 함께 전파되었습니다.

코드 9-1 잔차 연결 의사코드
x = ..# 입력 텐서residual = x# 원본 입력을 별도로 저장합니다. 이를 잔차라고 합니다.x = block(x)# 이 계산 블록은 파괴적이거나 잡음이 있을 수 있지만 괜찮습니다.x = add([x, residual])# 원본 입력을 층의 출력에 더합니다. 따라서 최종 출력은 항상 원본 입력의 전체 정보를 보존합니다.
입력을 블록의 출력에 다시 더하는 것은 출력 크기가 입력과 같아야 한다는 것을 의미합니다. 하지만 블록에 필터 개수가 늘어난 합성곱 층이나 최대 풀링 층이 들어있는 경우 그렇지 않습니다. 이런 경우 활성화 함수가 없는 1 x 1 Conv2D 층을 사용하여 잔차를 원하는 출력 크기로 선형적으로 투영할 수 있습니다. 블록에 있는 합성곱 층은 패딩 때문에 공간 방향으로 다운 샘플링 되지 않도록 일반적으로 padding=”same”을 사용합니다.
코드 9-2 필터 개수가 변경되는 잔차 블록
from tensorflow import keras
from tensorflow.keras import layers
input = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs)
residual = x# 잔차를 따로 저장합니다.# 잔차 블록에 해당하는 층입니다.# 이 층은 출력 필터를 32개에서 64개로 증가시킵니다.# 패딩으로 인해 다운 샘플링이 되지 않도록 padding="same"을 사용합니다.
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
# 잔차는 현재 32개의 필터만 있으므로 1 x 1 Conv2D를 사용하여 적절한 크기로 투영합니다.
residual = layers.Conv2D(64, 1)(residual)
x = layers.add([x, residual])# 이제 블록 출력과 잔차의 크기(모양)이 같으므로 더할 수 있습니다.
코드 9-3 최대 풀링 층을 가진 잔차 블록
input = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation="relu")(inputs)
residual = x# 잔차를 따로 저장합니다.# 잔차 블록에 해당하는 층입니다.# 이 층은 출력 필터를 32개에서 64개로 증가시킵니다.# 패딩으로 인해 다운 샘플링이 되지 않도록 padding="same"을 사용합니다.x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
x = layers.MaxPooling2D(2, padding="same")(x)
# 최대 풀링 층으로 인한 다운 샘플링을 맞추기 위해 잔차 투영에 strides=2를 사용합니다.residual = layers.Conv2D(64, 1, strides=2)(residual)
x = layers.add([x, residual])
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Rescaling(1./255)(inputs)
# 잔차 연결을 가진 합성곱 블록을 적용하는 유틸리티 함수. 선택적으로 MaxPooling을 추가합니다.def residual_block(x, filters, pooling=False):
residual = x
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
x = layers.Conv2D(filters, 3, activation="relu", padding="same")(x)
if pooling: # MaxPooling을 사용하면 잔차를 원하는 크기로 투영하기 위해 strides=2인 합성곱을 추가합니다.
x = layers.MaxPooling2D(2, padding="same")(x)
residual = layers.Conv2D(filters, 1, strides=2)(residual)
elif filters != residual.shape[-1]: # 채널수를 맞추기 위한 1 x 1 Conv2D입니다.
residual = layers.Conv2D(filters, 1)(residual)
x = layers.add([x, residual])
return x
x = residual_block(x, filters=32, pooling=True)
x = residual_block(x, filters=64, pooling=True)
x = residual_block(x, filters=128, pooling=False) # 마지막 블록은 바로 다음에 전역 평균 풀링을 사용하기 때문에 최대 풀링이 필요하지 않습니다.
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary()
3.3 배치 정규화
정규화(normalization)는 머신 러닝 모델에 주입되는 샘플들을 균일하게 만드는 광범위한 방법입니다. 이 방법은 모델이 학습하고 새로운 데이터에 잘 일반화되도록 돕습니다. 데이터 정규화의 가장 일반적인 형태는 이미 이 책에서 여러 번 나왔습니다. 데이터에서 평균을 빼서 데이터를 원점에 맞추고 표준 편차로 나누어 데이터의 분산을 1로 만드는 것입니다. 즉, 데이터가 정규 분포(가우스 분포)를 따른다고 가정하고 이 분포를 원점에 맞추고 분산이 1이 되도록 조정한 것입니다.
normalized_data = (data - np.mean(data, axis=...)) / np.std(data, axis=...)
이 책의 이전 예제들은 모델에 데이터를 주입하기 전에 정규화했습니다. 하지만 데이터 정규화는 네트워크에서 일어나는 모든 변환 후에도 필요할 수 있습니다. Dense나 Conv2D 층에 들어가는 데이터의 평균이 0이고 분산이 1이더라도 출력되는 데이터가 동일한 분포를 가질 것이라고 기대하기 어렵습니다. 활성화 함수의 출력을 정규화하면 도움이 될까요?
- *배치 정규화(batch normalization)**가 바로 이런 역할을 합니다. 배치 정규화는 2015년 아이오페와 세게디가 제안한 층의 한 종류입니다. 훈련하는 동안 평균과 분산이 바뀌더라도 이에 적응하여 데이터를 정규화합니다. 훈련하는 동안 현재 배치 데이터의 평균과 분산을 사용하여 샘플을 정규화합니다(대표성을 가질 만큼 충분히 큰 배치 데이터를 얻을 수 없는)추론 에서는 본 배치 데이터에서 구한 평균과 분산의 지수 이동 평균을 사용합니다.
원본 논문에서 배치 정규화는 ‘내부 공변량 변화(internal covariate shift)를 감소’시키기 때문이라고 언급되었지만, 배치 정규화가 왜 도움이 되는지 확실히 아는 사람은 없습니다. 다양한 가설이 있지만 확실한 것은 없습니다. 딥러닝에서는 이런 것이 많습니다. 딥러닝은 정확히 과학이라기보다 끊임없이 변화하고 경험적으로 추구되는 엔지니어링 모범 사례의 집합체이며 믿기 힘들 설명으로 얽혀있습니다. 이따금 읽고 있는 책이 어떻게 해야 하는지 알려 주지만 왜 작동하는지 만족스럽게 설명하지 못한다는 것을 느낄것입니다. 이는 방법은 알지만 이유는 모르기 때문입니다. 믿을 수 있는 설명이 있다면 이를 꼭 언급하겠습니다.
실제로 배치 정규화의 주요 효과는 잔차 연결과 매우 흡사하게 그레이디언트의 전파를 도와주는 것으로 보입니다. 결국 더 깊은 네트워크를 구성할 수 있습니다.
x = ...
x = layers.Conv2D(32, 3, use_bias=False(x)# Conv2D 출력이 정규화되기 때문에 편향 벡터가 필요하지 않습니다.x = layers.BatchNormalization()(x)
Note
Dense 층과 Conv2D 층은 모두 편향 벡터를 가집니다. 학습되는 이 변수는 층을 순순한 선형 변환이 아니라 아핀 변환으로 만드는 것이 목적입니다. 예를 들어 Conv2D는 $y = conv(x, kernal) + bias$를 반환하고 Dense는 $y = dot(x, kernel) + bias$를 반환합니다. 정규화 단계는 층의 출력을 평균을 0에 맞추기 땜누에 BtachNormalization을 사용할 때 편향 벡터가 더 이상 필요하지 않습니다. use_bias=False 옵션을 사용하면 편향을 제외한 층을 만들 수 있는데, 이렇게 하면 층을 약간 더 가볍게 만들 수 있습니다.
중요한 점은 일반적으로 활성화 층 이전에 배치 정규화층을 놓는 것이 좋습니다(아직 논란의 여지가 있습니다.)
코드 9-4 피해야 할 배치 정규화 사용법
x = layers.Conv2D(32, 3, activation=”relu”)(x)
x = layers.BatchNormalization()(x)
코드 9-5 배치 정규화 사용법 : 활성화 층이 마지막에 온다.
x = layers.Conv2D(32, 3, use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
배치 정규화와 미세 조정
배치 정규화는 여러 특이 사항이 있습니다. 대표적인 것 중 하나로 미세 조정과 관련이 있습니다.
BatchNormalization 층이 있는 모델을 미세 조정(fine tuning)할 때 이 층들을 동결하는 것이 좋습니다.(trainable=False로 설정) 그렇지 않으면 내부 평균과 분산이 계속 업데이트되어 Conv2D 층에 적용할 때 매우 작은 업데이트를 방해할 수 있습니다.
3.4 깊이별 분리 합성곱
Conv2D를 대체하면서 더 작고 더 가볍고 모델의 성능을 몇 퍼센트 높을 수 있는 층이 있다면 어떨까요?
이것이 깊이별 분리 합성곱(depthwise separable convolution) 층이 하는 일입니다. (케라스에서는 SeparableConv2D에 구현되어 있습니다.) 이 층은 입력 채널별로 따로따로 공간 방향의 합성곱을 수행합니다. 그 다음 그림 9-10과 같이 점별 합성곱(pointwise convolution)(1 x 1 합성곱)을 통해 출력 채널을 합칩니다.
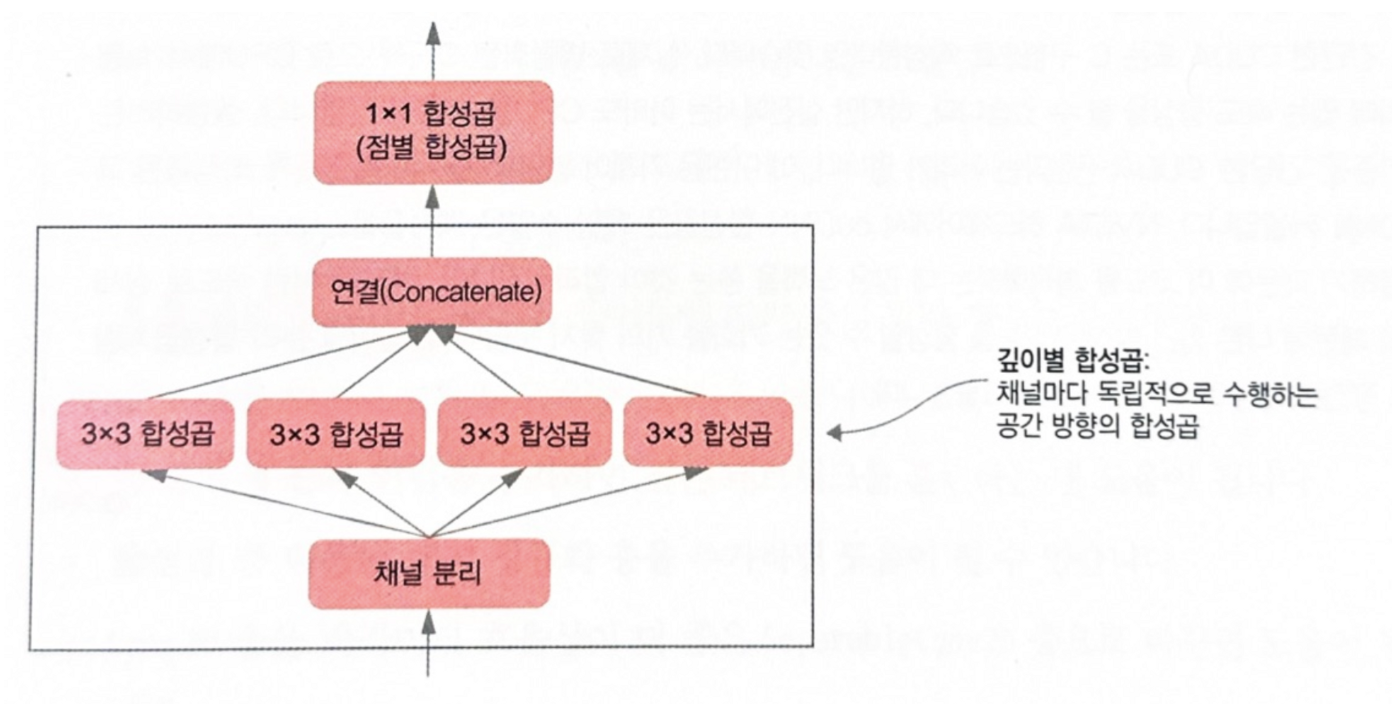
이는 공간 특성의 학습과 채널 방향 특성의 학습을 분리하는 효과를 냅니다. 합성곱의 이미지 상의 패턴이 특정 위치에 묶여 있지 않다는 가정에 의존하는 것처럼, 깊이별 분류 합성곱은 중간 활성화에 있는 공간산의 위치가 높은 상관관계를 가지지만 채널 간에는 매우 독립적이라는 가정에 의존합니다. 심층 신경망에 의해 학습되는 이미지 표현의 경우 이 가정이 일반적으로 맞기 때문에 훈련 데이터를 더 효율적으로 사용하게 도와주는 유용한 가정입니다.
깊이별 분리 합성곱은 일반 합성곱보다 훨씬 적은 개수의 파라미터를 사용하고 더 적은 수의 연산을 수행하면서 유사한 표현 능력을 가지고 있습니다. 수렴이 더 빠르고 쉽게 과대적합되지 않는 작은 모델을 만듭니다. 이런 장점은 제한된 데이터로 밑바닥부터 작은 모델을 훈련할 때 특히 중요합니다.
대규모 모델에 적용된 사례로는 케라스에 포함된 고성능 컨브넷인 Xception 구조의 기반으로 깊이별 분리 합성곱에 사용되었습니다. 필자의 논문 “Xception: Deep Learning with Depthwise Seaprable Convolution”에서 깊이별 분리 합성곱에 대한 자세한 이론적 배경을 읽을 수 있습니다.
하드웨어, 소프트웨어, 알고리즘의 공진화(co-evolution)
3 x 3 윈도, 입력 채널이 64개, 출력 채널이 64개인 일반 합성곱을 생각해 보죠. 훈련 가능한 파라미터는 3 * 3 * 64 * 64 = 36864개 입니다. 이를 이미지에 적용하면 파라미터 개수에 비례하는 부동 소수점 연산을 많이 실행합니다. 반면 동일한 설정에서 분리 합성곱의 경우 훈련 가능한 파라미터는 3 * 3 * 64 + 64 * 64 = 4672개이며, 이에 비례하여 부동 소수점 연산이 더 적습니다.
하지만 병렬화된 C 구현으로 CPU에서 실행하면 의미 있는 속도 향상을 얻을 수 있지만, 실제로는 GPU를 활용할 것입니다. 실행하려는 이 알고리즘은 ‘간단한’ CUDA 구현과는 거리가 멉니다. 이 구현은 기계어 명령 수준까지 특별하게 최적화된 코드인 cuDNN 커널입니다.
즉, 이론적으로는 깊이별 분리 합성곱이 빠른 학습과 좋은 성능을 기대할 수 있지만, 현실적인 하드웨어 개발 방향이 다르므로 인해 현재는 등한시 되고 있습니다.
3.5 Xception 유사 모델에 모두 적용하기
- 모델은 반복되는 층, 즉 블록으로 조직되어야 합니다. 블록은 일반적으로 여러 개의 합성곱 층과 최대 풀링 층으로 구성됩니다.
- 특성 맵의 공간 방향 크기가 줄어듦에 따라 층의 필터 개순는 증가해야 합니다.
- 깊고 좁은 아키텍처가 넓고 얕은 것보다 낫습니다.
- 층 블록에 잔차 연결을 추가하면 깊은 네트워크를 훈련하는데 도움이 됩니다.
- 합성곱 층 다음에 배치 정규화 층을 추가하면 도움이 될 수 있습니다.
- Conv2D 층을 파라미터 효율적인 더 좋은 SeparableConv2D 층으로 바꾸면 도움이 될 수 잇습니다.
inputs= keras.Input(shape=(180, 180, 3))
x= data_augmentation(inputs)
x= layers.Rescaling(1./255)(x)
x= layers.Conv2D(filters=32, kernel_size=5, use_bias=False)(x)
for sizein [32, 64, 128, 256, 512]:
residual= x
x= layers.BatchNormalization()(x)
x= layers.Activation("relu")(x)
x= layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x= layers.BatchNormalization()(x)
x= layers.Activation("relu")(x)
x= layers.SeparableConv2D(size, 3, padding="same", use_bias=False)(x)
x= layers.MaxPooling2D(3, strides=2, padding="same")(x)
residual= layers.Conv2D(
size, 1, strides=2, padding="same", use_bias=False)(residual)
x= layers.add([x, residual])
x= layers.GlobalAveragePooling2D()(x)
x= layers.Dropout(0.5)(x)
outputs= layers.Dense(1, activation="sigmoid")(x)
model= keras.Model(inputs=inputs, outputs=outputs)
4. 컨브넷이 학습한 것 해석하기
컴퓨터 비전 애플리케이션을 구축할 때 근복적인 문제는 해석 가능성(interpretability)입니다. 특정 이미지에서 볼 수 있는 것은 트럭뿐인데 모델은 냉장고가 들어 있다고 생각하는 이유가 무엇일까요?
딥러닝 모델을 흔히 “블랙받스” 같다고 자주 이야기합니다. 모델이 학습한 표현을 사람이 이해하기 쉬운 형탵로 뽑아내거나 제시하기 어렵기 때문입니다. 일부 딥러닝 모델에서는 이 말이 어느정도 맞지만 컨브넷에서는 전혀 아닙니다. 컨브넷의 표현은 시각적인 개념을 학습한 것이기 때문에 시각화하기 아주 좋습니다.
- 컨브넷 중간층의 출력(중간층에 있는 활성화(Feature Map))을 시각화하기
- 연속된 컨브넷 층이 입력을 어떻게 변형시키니는지 이해하고 개별적인 컨브넷 필터의 의미를 파악하는데 도움이 됩니다.
- 컨브넷 필터를 시각화하기
- 컨브넷의 필터가 찾으려는 시각적인 패턴과 개념이 무엇인지 상세하게 이해하는데 도움이 됩니다
- 클래스 활성화에 대한 히트맵(heatmap)을 이미지에 시각화하기
- 어떤 클래스에 속하는 데 이미지의 어느 부분이 기여했는지 이해하고 이미지에서 객체의 위치를 추정(localization)하는데 도움이 됩니다.
4.1 중간 활성화(Feature Map) 시각화
from tensorflow import keras
model = keras.models.load_model("convnet_from_scratch_with_augmentation.keras")
model.summary()
'''
출력 결과
Model: "model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 180, 180, 3)] 0
sequential (Sequential) (None, 180, 180, 3) 0
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d_11 (Conv2D) (None, 178, 178, 32) 896
max_pooling2d_6 (MaxPooling (None, 89, 89, 32) 0
2D)
conv2d_12 (Conv2D) (None, 87, 87, 64) 18496
max_pooling2d_7 (MaxPooling (None, 43, 43, 64) 0
2D)
conv2d_13 (Conv2D) (None, 41, 41, 128) 73856
max_pooling2d_8 (MaxPooling (None, 20, 20, 128) 0
2D)
conv2d_14 (Conv2D) (None, 18, 18, 256) 295168
max_pooling2d_9 (MaxPooling (None, 9, 9, 256) 0
2D)
conv2d_15 (Conv2D) (None, 7, 7, 256) 590080
flatten_3 (Flatten) (None, 12544) 0
dropout (Dropout) (None, 12544) 0
dense_3 (Dense) (None, 1) 12545
=================================================================
Total params: 991,041
Trainable params: 991,041
Non-trainable params: 0
_________________________________________________________________
'''
그 다음에 이 네트워크를 훈련할 때 사용했던 이미지가 아닌 다른 고양이 사진 하나를 입력 이미지로 선택합니다.
코드 9-6 1개의 이미지 전처리 하기
from tensorflow import keras
import numpy as np
img_path = keras.utils.get_file(
fname="cat.jpg",
origin="<https://img-datasets.s3.amazonaws.com/cat.jpg>")
def get_img_array(img_path, target_size):
img = keras.utils.load_img(
img_path, target_size=target_size)
array = keras.utils.img_to_array(img)
array = np.expand_dims(array, axis=0)
return array
img_tensor = get_img_array(img_path, target_size=(180, 180))
코드 9-7 테스트 이미지 출력
import matplotlib.pyplotas plt
plt.axis("off")
plt.imshow(img_tensor[0].astype("uint8"))
plt.show()
코드 9-8 층 활성화(Feature Map)을 반환하는 모델 만들기
from tensorflow import layers
layer_outputs = []
layer_names = []
for layer in model.layers:
if isinstance(layer, (layers.Conv2D, layers.MaxPooling2D)):
layer_outputs.append(layer.output)
layer_names.append(layer.name)
activation_model = keras.Model(inputs=model.input, outputs=layer_outputs)
모델을 이렇게 구성하면 입력 이미지가 주입될 때 원본 모델의 활성화 값을 모두 반환합니다. 7장에서 다중 출력 모델에 배운 이후로 이 책에서 이 모델이 처음 나오는 다중 출력 모델입니다.
코드 9-9 활성화 계산하기
activations = activation_model.predict(img_tensor)
코드 9-10 5번 index(6번째) 채널 시각화하기
import matplotlib.pyplot as plt
plt.matshow(first_layer_activation[0, :, :, 5], cmap="viridis")
plt.show()

코드 9-11 모든 층의 활성화에 있는 전체 채널 시각화하기
images_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
n_cols = n_features // images_per_row
display_grid = np.zeros(((size + 1) * n_cols - 1,
images_per_row * (size + 1) - 1))
for col in range(n_cols):
for row in range(images_per_row):
channel_index = col * images_per_row + row
channel_image = layer_activation[0, :, :, channel_index].copy()
if channel_image.sum() != 0:
# 채널 값을 [0, 255] 범위로 정규화합니다.# 모두 0인 채널은 error를 유발하므로 넘어갑니다.channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype("uint8")
display_grid[
col * (size + 1): (col + 1) * size + col,
row * (size + 1) : (row + 1) * size + row] = channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.axis("off")
plt.imshow(display_grid, aspect="auto", cmap="viridis")

- 첫 번째 층은 여러 종류의 에지(edge) 감지기를 모아놓은 것 같습니다. 이 단계의 Feature Map에는 초기 이미지에 있는 거의 모든 정보가 유지됩니다.
- 층이 깊어질수록 활성화는 점점 더 추상적으로 되고 시각적으로 이해하기 어려워집니다. ‘고양이 귀’와 ‘고양이 눈’처럼 고수준 개념을 인코딩하기 시작합니다. 깊은 층의 표현은 이미지의 시각적 콘텐츠에 관한 정보가 점점 줄고 이미지의 클래스에 관한 정보가 점점 증가합니다.
- 비어 있는 활성화가 층이 깊어짐에 따라 늘어납니다. 첫 번째 층에서는 거의 모든 필터가 입력 이미지에 활성화 되었지만 층을 올라가면서 활성화되지 않는 필터들이 생깁니다. 이는 필터에 인코딩된 패턴이 입력 이미지에 나타나지 않았다는 것을 의미합니다.
4.2 컨브넷 필터 시각화하기
컨브넷이 학습한 필터를 조사하는 또 다른 간편한 방법은 각 필터가 반응하는 시각적 패턴을 그려보는 것입니다.
빈 입력 이미지에서 시작해서 특정 필터의 응답을 최대화하기 위해 컨브넷 입력 이미지에 경사 상승법을 적용합니다. 결과적으로 입력 이미지는 선택된 필터가 최대로 응답하는 이미지가 될 것입니다.
ImageNet에서 사전 훈련된 Xception 모델의 필터를 사용해보겠습니다. 전체 과정은 간단합니다. 특정 합성곱 층의 한 필터 값을 최대화하는 손실 함수를 정의합니다. 이 활성화 값을 최대화하기 위해 입력 이미지를 변경하도록 확률적 경사 상승법을 사용합니다. 이는 GradientTape 객체를 사용하여 저수준 훈련 루프를 구현해야합니다.
코드 9-12 Xception 합성곱 기반 모델 만들기
model = keras.applications.xception.Xception(
weights="imagenet",
include_top=False)
코드 9-13 Xception에 있는 모든 합성곱 층의 이름 출력하기
for layer in model.layers:
if isinstance(layer, (keras.layers.Conv2D, keras.layers.SeparableConv2D)):
print(layer.name)
코드 9-14 특성 추출 모델 만들기
layer_name = “block3_sepconv1”# Xception 합성곱 기반에 있는 다른 층의 이름으로 대체 가능합니다.layer = model.get_layer(name=layer_name)
# model.input과 layer.output을 사용해서 입력 이미지가 주어졌을 때 해당 층의 출력을 반환하는 모델을 만듭니다.feature_extractor = keras.Model(input=model.input, outputs=layer.output)
이 모델을 사용하려면 어떤 입력 데이터에서 모델을 호출하면 됩니다.
코드 9-15 특성 추출 모델 사용하기
activation = feature_extractor(
keras.applications.xception.preprocess_input(img_tensor)
)
특성 추출 모델을 사용해서 입력 이미지가 층의 필터를 얼마나 활성화하는지 정량화된 스칼라 값을 반환하는 함수를 정의해 보겠습니다. 이 함수가 경사 상승법 과정 동안 최대화할 “손실 함수”가 됩니다.
import tensorflow as tf
def compute_loss(image, filter_index):
activation = feature_extractor(image)
# (Optional)손실에 경계 픽셀을 제외 시켜 경계에 나타나는 부수 효과를 제외시킵니다.# 활성화 테두리를 따라 두 픽셀을 제외합니다.
filter_activation = activation[:, 2:-2, 2:-2, filter_index]
return tf.reduce_mean(filter_activation)# 해당 index의 필터에 대한 활성화 값의 평균을 반환합니다.
model.predict(x)와 model(x)의 차이
y = model.predict(x)와 y = model(x) 둘 다 ‘입력 x로 모델을 실행하여 얻은 출력 y’를 의미합니다. 하지만 완전이 동일하지는 않습니다. predict() 는 배치로 데이터를 순회하면서 모델 출력을 넘파이 배열로 추출합니다. 대략 다음과 같습니다.
def predict(x):
y_batches = []
for x_batches inget_batches(x):
y_batch = model(x).numpy()
y_batches.append(y_batch)
return y_batches
이는 predict(x) 메서드가 매우 큰 배열을 처리할 수 있다는 의미입니다. 반면 model(x) 는 모두 메모리 내에서 처리하며 확장성이 없습니다. 하지만 predict(x) 는 미분 가능하지 않습니다. 즉, GradientTape 범위 안에서 이 메서드를 호출할 때 그레이디언트를 구할 수 없습니다.
모델 호출의 그레디언트를 계산하려면 model(x)를 사용하고 출력 값만 필요하다면 predict(x)를 사용해야 합니다. 다른 말로 하면 저수준 하강법 루프를 작성하는게 아니라면 항상 predict(x) 메서드를 사용해도 무방합니다.
GradientTape를 사용해서 경사 상승법 단계를 구성해 보죠. 속도를 높이기 위해 @tf.function 데코레이터를 사용하겠습니다.
경사 상승법 과정을 부드럽게 하기 위해 사용하는 한 가지 기법은 그레디언트 텐서를 L2 노름(텐서에 있는 값을 제곱한 합의 제곱근)으로 나누어 정규화하는 것입니다. 이렇게 하면 입력이 이미지에 적용할 수정량의 크기를 항상 일정 범위 안에 놓을 수 있습니다.
코드 9-16 확률적 경사 상승법을 사용한 손실 최대화
@tf.function
def gradient_ascent_step(image, filter_index, learning_rate):
with tf.GradientTape() as tape:
# GradientTape은 텐서플로 변수만 자동으로 감시하기에 명시적으로 지정합니다.
tape.watch(image)
# 현재 이미지가 필터를 얼마나 활성화하는지 나타내는 스칼라 손실을 계산합니다.
loss = compute_loss(imagem filter_index)
grads = tape.gradient(loss, image)# image에 대한 손실의 그레디언트를 계산하비다.
grads = tf.math.l2_normal(grads)# 그레디언트 정규화 트릭을 적용합니다.
image += learning_rate * grads# 필터를 더 강하게 하는 방향으로 이미지를 조금 update합니다.return image
코드 9-17 필터 시각화 생성 함수
img_width = 200
img_height = 200
def generate_filter_pattern(filter_index):
iterations = 30 # 횟수
learning_rate = 10. # learning_rate
image = tf.random.uniform(
minval=0.4,
maxval=0.6,
shape=(1, img_width, img_height, 3)) # 처음에 random한 값을 초기화. 중심을 0.5로
for i in range(iterations):
image = gradient_ascent_step(image, filter_index, learning_rate)
return image[0].numpy()
**def** deprocess_image(image):
image**-=** image**.**mean()
image**/=** image**.**std()
image***=** 64
image **+=** 128
image **=** np**.**clip(image, 0, 255)**.**astype("uint8")
image **=** image[25:**-**25, 25:**-**25, :]
**return** image
plt**.**axis("off")
plt**.**imshow(deprocess_image(generate_filter_pattern(filter_index**=**2)))
plt**.**show()
코드 9-19 층에 있는 모든 필터의 응답 패턴에 대한 그리드 생성하기
all_images= []
for filter_indexin range(64):
print(f"{filter_index}번 필터 처리중")
image= deprocess_image(
generate_filter_pattern(filter_index)
)
all_images.append(image)
margin= 5
n= 8
cropped_width= img_width- 25* 2
cropped_height= img_height- 25* 2
width= n* cropped_width+ (n- 1)* margin
height= n* cropped_height+ (n- 1)* margin
stitched_filters= np.zeros((width, height, 3))
for iin range(n):
for jin range(n):
image= all_images[i* n+ j]
stitched_filters[
(cropped_width+ margin)* i : (cropped_width+ margin)* i+ cropped_width,
(cropped_height+ margin)* j : (cropped_height+ margin)* j
+ cropped_height,
:,
]= image
keras.utils.save_img(
f"filters_for_layer_{layer_name}.png", stitched_filters)

- 모델에 있는 천 번째 층의 필터는 간단한 대각성 방향의 에지와 색깔을 인코딩합니다.
- block4_sepconv1과 같이 조금 더 나중에 있는 필터는 에지나 색깔의 조합으로 만들어진 간단한 질감을 인코딩합니다.
- 더 뒤에 잇는 층의 필터는 깃털, 눈, 나뭇잎 등 자연적인 이미지에서 찾을 수 있는 질감을 닮아가는 것 같습니다.
4.3 클래스 활성화의 히트맵 시각화
모델 해석 가능성(model interpretability)이라고 부르는 분야. 또한, 이미지에 특정 물체가 있는 위치를 파악하는데 사용할 수도 이씃ㅂ니다.
이 종류의 기법을 일반적으로 클래스 활성화 맵(Class Activation Map, CAM)이라고 합니다. 클래스 활성화 히트맵은 특정 출력 클래스에 대해 입력 이미지의 모든 위치를 계산한 2D 점수 그리드입니다. 클래스에 대해 각 위치가 얼마나 중요한지 알려줍니다
Grad-CAM은 입력 이미지가 주어지면 합성곱 층에 있는 특성 맵의 출력을 추출합니다. 그 다음 특성 맵의 모든 채널 출력에 채널에 대한 클래스의 그레디언트 평균을 곱합니다. 이 기법을 직관적으로 다음과 같이 설명할 수 있습니다. “입력 이미지가 각 채널을 활성화 하는 정도”에 대한 공간적인 맵을 “클래스에 대한 각 채널의 중요도”로 가중치를 부여하여 “입력 이미지가 클래스를 활성화하는 정도”에 대한 공간적인 맵을 만드는 것입니다.
코드 9-20 사전 훈련된 가중치로 Xception 네트워크 로드하기
model = keras.applications.xception.Xception(weights=”imagenet”)# 최상위 밀집 연결 층 포함
코드 9-21 Xception 모델에 맞게 입력 이미지 전처리하기
img_path = keras.utils.get_file(
fname="elephant.jpg",
origin="<https://img-datasets.s3.amazonaws.com/elephant.jpg>")
def get_img_array(img_path, target_size):
img = keras.utils.load_img(img_path, target_size=target_size)
array = keras.utils.img_to_array(img)
array = np.expand_dims(array, axis=0)
array = keras.applications.xception.preprocess_input(array)
return array
img_array = get_img_array(img_path, target_size=(299, 299))
입력으로 넣은 아프리카 코끼리에 대한 예측 클래스의 결과가 다음과 같이 나와씃ㅂ니다.
preds = model.predict(img_array)
print(keras.applications.xception.xception.decode_predict(preds, top=3)[0])
# 출력 결과 0.869, 0.07, 0.02
- 아프리카 코끼리(87%), 코끼리(7%), 인도 코끼리(2%)
이미지에서 가장 아프리카 코끼리 같다고 느끼는 부위를 시각화하기 위해 Grad-CAM 처리 과정을 구현하겠습니다.
먼저 입력 이미지를 마지막 합성곱 층의 활성화에 매핑하는 모델을 만듭니다.
코드 9-22 마지막 합성곱 출력을 반환하는 모델 만들기
last_conv_layer_name = "block14_sepconv2_act"
classifier_layer_names = [
"avg_pool",
"predictions",
]
last_conv_layer = model.get_layer(last_conv_layer_name)
last_conv_layer_model = keras.Model(model.input, last_conv_layer.output)
그 다음 마지막 합성곱 층의 활성화(Feature Map)을 최종 클래스 예측에 매핑하는 모델을 만듭니다.
코드 9-23 마지막 합성곱 출력 위에 있는 분류기에 적용하기 위한 모델 만들기
classifier_input = keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in classifier_layer_names:
x = model.get_layer(layer_name)(x)
classifier_model = keras.Model(classifier.input, x)
그 다음 마지막 합성공 층의 Feature Map에 대한 최상위 예측 클래스의 그레디언트를 계산합니다.
코드 9-24 최상위 예측 클래스의 그레디언트 계산하기
import tensorflow as tf
with tf.GradientTape() as tape:
# 마지막 Feature Map을 계산하고 그레디언트 테이프로 감쌉니다.last_conv_layer_output = last_conv_layer_model(img_array)
tape.watch(last_conv_layer_output)
preds = classifier_model(last_conv_layer_output)
# 최상위 예측 클래스에 해당하는 활성화 채널을 추출합니다.top_pred_index = tf.argmax(preds[0])
top_class_channel = preds[:, top_pred_index]
# 마지막 합성곱 층의 출력 특성 맵에 대한 최상위 예측 클래스의 그레디언트를 계산합니다.grads = tape.gradient(top_class_channel, last_conv_layer_output)
코드 9-25 이제 그레디언트를 평균하고 채널 중요도 가중치 적용하기
# 이 벡터는 각 원소는 어떤 채널에 대한 그레디언트의 평균 강도입니다.# 최상위 예측 클래스에 대한 각 채널의 중요도를 정량화 한 것입니다.# (1, 10, 10, 2048) -> (2048, )로 변환하는 과정pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2)).numpy()
last_conv_layer_output = last_conv_layer_output.numpy()[0]
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, -1] *= pooled_prads[i]
# 이 벡터는 각 원소는 어떤 채널에 대한 그레디언트의 평균 강도입니다.# 최상위 예측 클래스에 대한 각 채널의 중요도를 정량화 한 것입니다.# (1, 10, 10, 2048) -> (2048, )로 변환하는 과정# grads 텐서의 평균값을 계산하여 pooled_grads를 얻습니다. (2048개의 값이 있는 1차원 배열)
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2)).numpy()
# last_conv_layer_output을 numpy 배열로 변환하고 첫 번째 원소를 선택합니다.# last_conv_layer_output은 (1, 10, 10, 2048)의 형태를 가지며, 첫 번째 원소를 선택하면 (10, 10, 2048) 형태의 numpy 배열이 됩니다.
last_conv_layer_output = last_conv_layer_output.numpy()[0]
# pooled_grads의 각 채널에 해당하는 값을 이용하여 last_conv_layer_output을 가중치로 곱합니다.
**# 마지막 차원의 크기(2048)만큼 반복하면서 각 채널에 해당하는 값을 해당 채널의 모든 원소에 곱합니다.**
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, i] *= pooled_grads[i]
# last_conv_layer_output의 마지막 차원(2048)을 평균하여 heatmap을 얻습니다.
**# heatmap은 (10, 10)의 형태를 가지며, 이는 각 위치에서의 중요도를 나타내는 값입니다.**
heatmap = np.mean(last_conv_layer_output, axis=-1)
# last_conv_layer_output과 heatmap의 형태를 출력합니다.
print(last_conv_layer_output.shape, heatmap.shape)
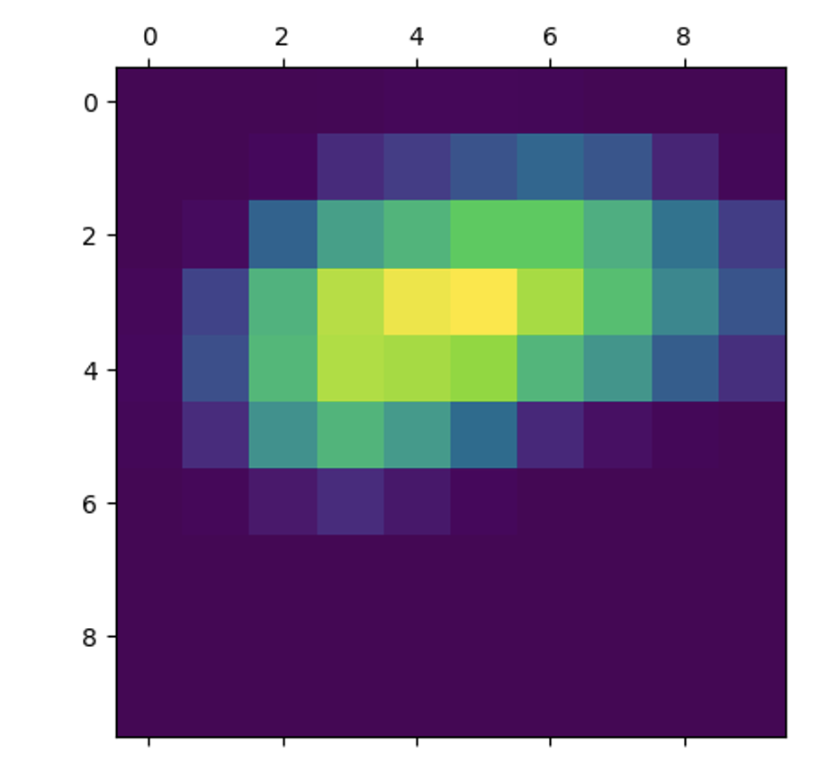
시각화를 위해 히트맵을 0과 1사이로 정규화하겠습니다.
코드 9-26 히트맵 후처리하기
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
plt.show()
코드 9-27 원본 이미지 위에 히트맵 그리기
import matplotlib.cm as cm
img = keras.utils.load_img(img_path)
img = keras.utils.img_to_array(img)
heatmap = np.uint8(255 * heatmap)
jet = cm.get_cmap("jet")
jet_colors = jet(np.arange(256))[:, :3]
jet_heatmap = jet_colors[heatmap]
jet_heatmap = keras.utils.array_to_img(jet_heatmap)
jet_heatmap = jet_heatmap.resize((img.shape[1], img.shape[0]))
jet_heatmap = keras.utils.img_to_array(jet_heatmap)
superimposed_img = jet_heatmap * 0.4 + img
superimposed_img = keras.utils.array_to_img(superimposed_img)
save_path = "elephant_cam.jpg"
superimposed_img.save(save_path)
